NEWS

|
This installment of Daftcube’s Dividends has three unrelated parts. They cover what I did this month, and during my brief hiatus in the beginning of January. This one’s quite a long one, so grab a snack and beverage! RoVerse Backend: Object-Relational MappingData, data, DATA! RoVerse deals with a lot of data. From a solar system database that is 200+ entries large, to realtime markets that must be able to handle potentially hundreds of transactions per second, structuring data in the right way can make the difference between a sluggish experience and a seamless one. One of the harder architectural challenges of any highly scalable cloud application is how to structure data such that it is both easy to persist and easy to operate upon when retrieved from its storage location. Today, we will discuss how we can solve this challenge in computer science by using object-oriented design principles and a technique called object-relational mapping. Why We Use Objects, and What They Are!Let’s start with the ‘object’ part of object-relational mapping. In computer science, we have many ways we can structure data and its associated behaviors. If you have done basic programming in Roblox Lua or another scripting language, you might be vaguely familiar with the “procedural” paradigm of programming. In functional programming, execution happens sequentially. In other words, the code runs each line in order, like an ordered procedure or list of tasks. Here’s an example image… 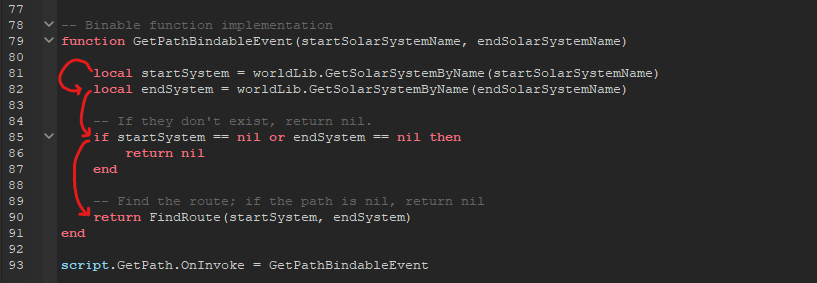 As you can see, each line of code runs one after the other. For storing temporary values, we can store data “locally” in functions, or “globally” if outside of functions. Local data only exists in functions and is thrown out once the function ends. Global variables can be accessed from anywhere in the program. However, procedural programming can get organizational issues if we want to build programs that have behavior that is closely related to its data. As an example, let’s try to see what the classic game Pong would look like in a procedural format…
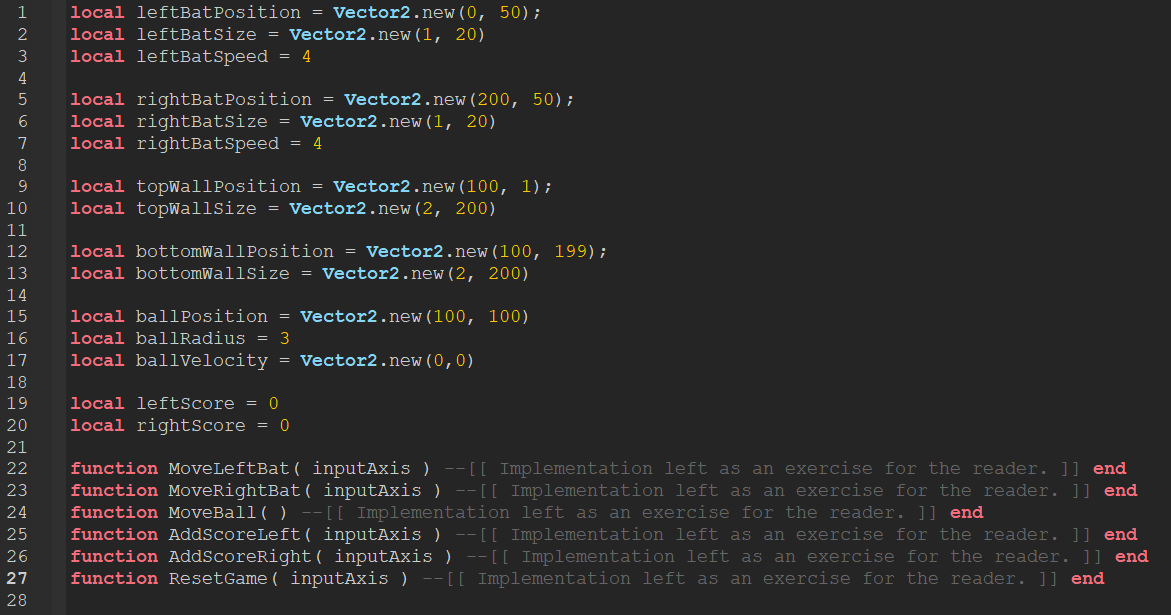 Cool, we pretty much have the overarching design of the game set up, and all we really must do is implement all of this. Procedural programming works well when either the project is simple, or the program’s data is more important than the behaviors we might give said data. However, in games, we often care about the behaviors more than just data. Consider the following example… Let’s say, we want to expand our pong game to have powerups! If the ball hits a powerup, the player who last hit the ball will get an effect. Let’s brainstorm a few…
So, with the first idea, it is painless to implement in our program design. All we must do is increase the ball’s velocity. However, for the second idea, we must add new balls to the game. We only have variables for a single ball, so we must declare additional variables to expand our functionality. In addition, we must give those extra balls behaviors, so let’s declare those too. 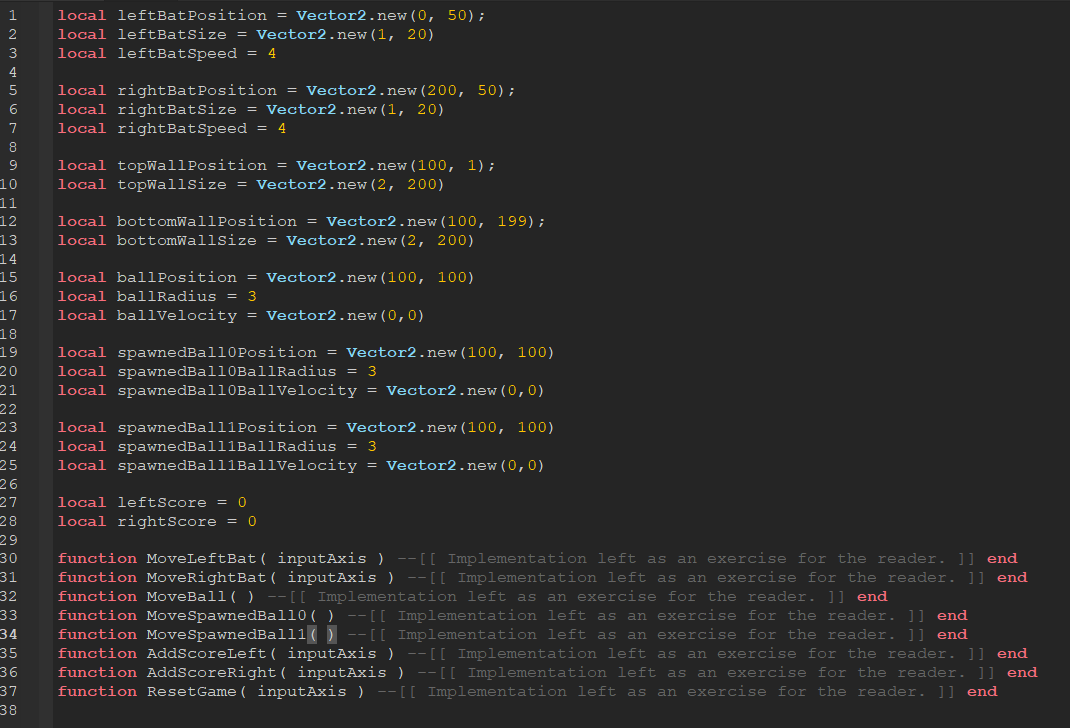 Now, one more change! The spawning powerup is a hit, but the players want more! Now we want our ball spawning powerup to spawn one hundred balls! Welp, I’m not going to even try declaring that many variables and functions. Sure, we could use arrays, but the code would still be a bit messy. What we need is a way to organize our code such that the data and its behaviors are bundled into one package. And, guess what! We have the technology! Well, we’ve had the technology for more than 20 years. Introducing: Objects! Object-oriented programming organizes a program into ‘objects’ that combine both data and its associated behaviors. For example, an object for a single ball in our pong game might look like this…  This has many benefits. First, when we organize our data this way, we can only work with data that is contained in our object. This separates the data and makes the entire codebase more organized and less confusing. Next, we can make (instantiate) as many instances of this object as we want at runtime. We could make a powerup that spawns 100,000 if we wanted to, and it wouldn’t be any extra work! Using class diagrams, we can also draw out what our entire game might look like if we made each part of it an object. 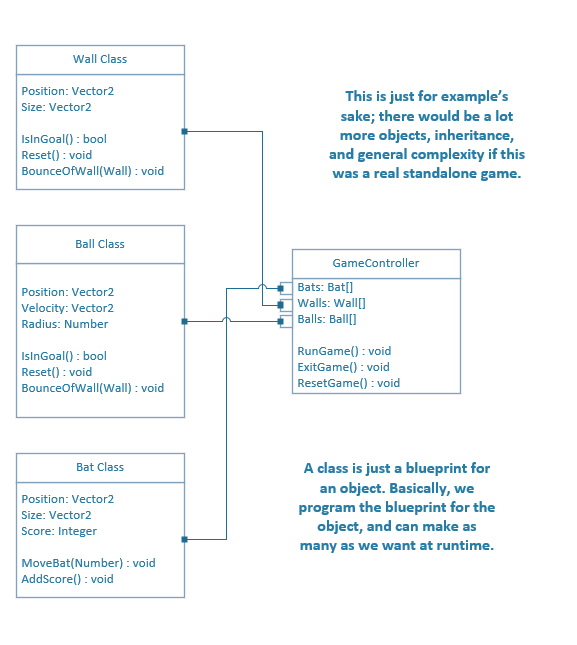 In the RoVerse Testbench, we use objects for so many different things! Here’s an example of a class definition for a solar system! 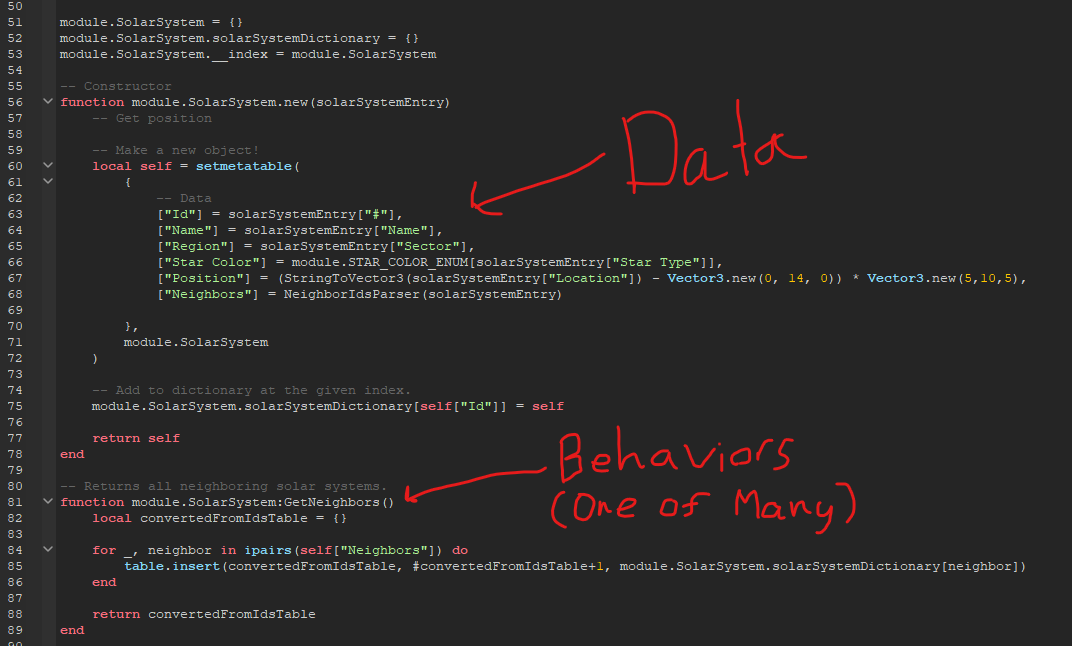 Now that we understand what objects are and why we use them, let’s discuss why adding a database to the equation makes things a bit more difficult. The “Relational Mapping” Part of ORMSo, what’s the “relational” part mean? Well, it refers to the type of database we are using. We chose to use a relational database to persist our backend data. In a relational database, entries are organized into tables. A table possesses a set number of unchanging columns that define what data types each entry has. Every row in the table represents a single entry. In other words, think of a fancy spreadsheet! Because relational databases have a fixed organization of data, they tend to be very fast to query. This is because our fixed organization allows us to make assumptions about how the database is organized and indexed. But, I’m not a database guy, so I don’t know how to explain much more than that. Below is a sample table from an iteration of our market code. 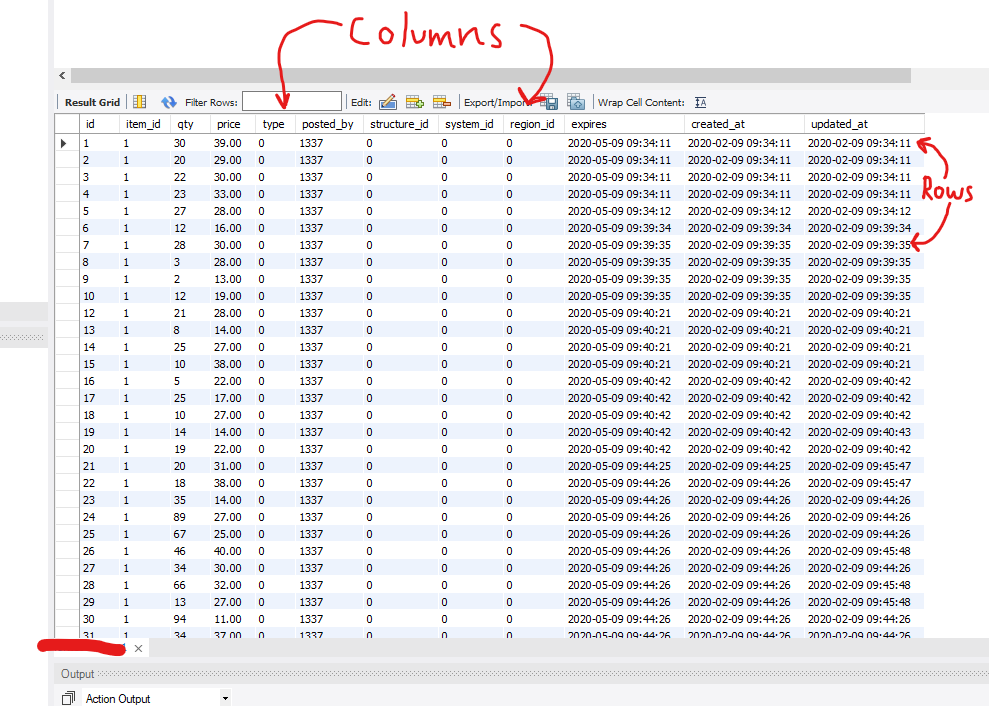 This is great, but we have a problem: how do we convert between our objects in memory and our rows in our database? The simple solution would be to write a function for each object to convert it into a query that the database could accept. This would work, but we would have a lot of repeating – or ‘boilerplate’ – code that does the same thing. Plus, both are structured and predictable ways of storing data, so there must be some way to automate the object conversion code. And there is a way to automate the code: use an Object-Relational Mapping library! An object-relational mapping library does exactly what you think it would; it provides functionality that automates the process of converting our objects into database entries and back again. We’re using Sequelize, which also provides a bunch of extra helpful features like built-in transaction support. (Remember last Daftcube’s Dividends for why we need transactions!) If you’re interested in how Sequelize works, it’s an open source project. Feel free to look at the documentation and source code on their website. In short, using an object-oriented principle called inheritance, we can create objects that already have the object-relational mapping out of the box. 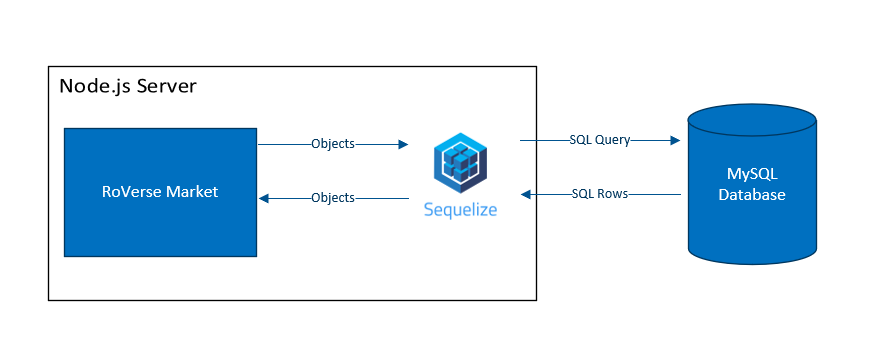 And that’s pretty much it, really! We solved several problems in this edition of Daftcube’s Dividends, including how to structure data in memory and in long-term storage, and how to convert between the two. Now, because some were curious about where I was for the last month, let’s talk about that! Daft's Research!I was recently invited by my electrical engineering professor to join his hardware lab! I got my own permanent desk with a computer with more cores than I can count on my fingers and more RAM than one would ever need! Our lab is trying to train neural networks to identify human emotions from facial expressions. Our main problem is that training neural networks requires a lot of sample data, and it’s just not feasible to invite thousands of people into the lab, record videos of various facial expressions, and then tag and archive them. To solve this problem, I’m building a way to generate our own dataset by rendering the videos we need using cinema-grade CG characters and open-source professional motion and facial capture animations. We figure that, if our CG animations are close enough to reality, the neural network should be able to use the footage as a solid foundation to identify real human faces. Of course, there is a chance this won’t work. It’s research, and it can happen. If it doesn’t work, my project isn’t useless; we’re also going to use it as a foundation to research new ways to send and render facial expressions over the network. My software will integrate with the lab’s experimental low-profile facial camera setup and convert its camera data into facial blendshape positions that can be sent over the network. Cool stuff! A side note: my teachers always told me that guess-and-check was sloppy. But, if you do it fast enough, it suddenly becomes “machine learning” and you can make $500,000 annually for it! Or, in my case, an unpaid undergraduate research position. It’s still super awesome and exciting though; I can call myself a proper researcher now! Testbench Status and ConclusionWe’ve been hitting targets at a rapid pace! I’m shocked, honestly. I still can’t give a date of release, (classic RoVerse :P ) but it should be sooner rather than later. I will also try to increase the dividends for you folks. Thanks for reading, and take care!
Comments are closed.
|
Archives
January 2023
Categories
All
AuthorsVaktus: Leader of the Vaktovian Empire and head of the RoVerse Project |
 RSS Feed
RSS Feed
